网页爬虫Web Scraper
v0.6.1 官方版大小:1.50 MB更新:2021/09/23
类别:网络辅助系统:Winll
分类分类
大小:1.50 MB更新:2021/09/23
类别:网络辅助系统:Winll
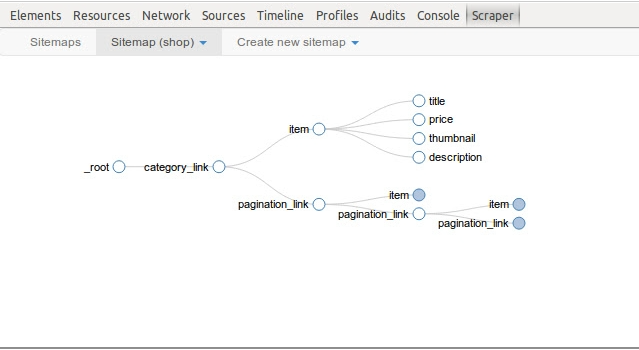
网页爬虫Web Scraper是一款chrome浏览器上的数据抓取工具,是一款浏览器插件工具,能够在网页上进行数据抓取,只需要进行简单设置,就能够获取你想要的数据,功能非常的强大,简介的画面风格,免费且易于使用,适合大多数人使用;有需要的朋友快来下载体验吧!
现代网络的网络数据提取工具,具有简单的点选式界面
免费且易于使用的网络数据提取工具,适合所有人使用。
通过一个简单的点选界面,只需几分钟的刮刀设置,就能从一个网站上提取成千上万的记录。
Web Scraper利用了一个由选择器组成的模块化结构,这些选择器指示刮刀如何遍历目标网站和提取哪些数据。由于这种结构,从现代和动态网站(如亚马逊、Tripadvisor、eBay)以及不太知名的网站中提取数据毫不费力。
数据提取在你的浏览器上运行,不需要在你的电脑上安装任何东西。你不需要python、php或javaScript编码经验就可以开始提取。此外,在Web Scraper Cloud中可以完全自动进行数据提取。
一旦数据被提取,可将其下载为CSV文件,可进一步导入excel、Google Sheets等。
Web Scraper是一个简单的网络搜刮工具,允许你使用许多高级功能来获得你正在寻找的确切信息。它提供的功能包括。
* 从多个网页中刮取数据。
* 多种数据提取类型(文本、图像、URL,以及更多)。
* 浏览搜刮的数据。
*从网站上导出搜刮的数据到Excel。
* 从动态页面(JavaScript+AJAX,无限滚动)刮取数据。
它只依赖于网络浏览器;因此,你不需要额外的软件就可以开始搜刮。
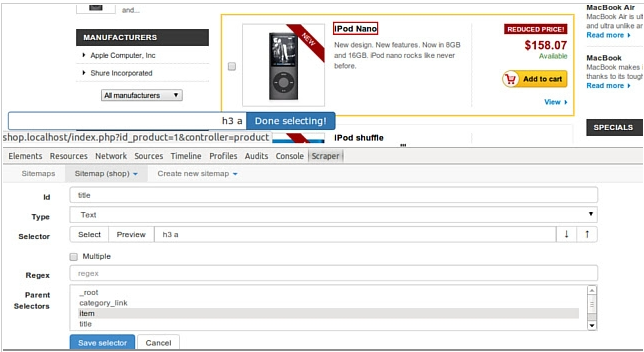
为了掌握网络搜刮技术,你只需要学习几个步骤。
1. 安装扩展程序,并在开发者工具中打开网络刮削器标签(必须放在屏幕底部)。
2. 创建一个新的网站地图。
3. 在网站地图中添加数据提取选择器。
4. 最后,启动搜刮器并导出搜刮的数据。
就这么简单!
1、刮多页
2、从动态页面
3、出口刮数据作为CSV
4、进口,出口的Sitemaps
5、只依赖于Chrome浏览器
6、提取数据(的JavaScript AJAX)
7、刮数据存储在本地存储或CouchDB的
8、浏览刮数据/> 3、多个数据选择类型
ghelper上网助手网络辅助362.00 KBv2.6.2 最新版
详情Global Speed(网页视频加速插件)网络辅助404.00 KB免费版
详情科达IPCSearch工程配置工具网络辅助7.50 MBv3.0.181002 官方版
详情Aircrackng(无线破解工具)网络辅助7.10 MBv1.5.2 中文免费版
详情chrome鼠标手势插件网络辅助42.00 KBv1.13.4 免费版
详情红蜘蛛多媒体网络教室7.2破解版网络辅助19.58 MBv7.2 build 1208 特别版
详情uBlock Origin广告过滤插件网络辅助5.00 MBv1.38.0 正式版
详情腾讯视频会员签到网络辅助2.03 MBv1.2 绿色免费版
详情Saladict沙拉查词网络辅助22.20 MBv7.20.0 官方版
详情Adobe flash player Plugin插件网络辅助2.17 MBv32.0.0.142 最新中文版
详情斐讯K2最新刷机固件(附华硕潘多拉固件)网络辅助26.20 MBv22.4.5.39 官方版
详情Pocket (火狐稍后阅读插件)网络辅助219.00 MBv3.0.6 最新版
详情艾德软件360推广助手网络辅助17.80 MBv1.0.6 官方版
详情Adblock for Chrome(谷歌浏览器广告拦截插件)网络辅助5.00 MBv3.43.0 免费版
详情海康摄像机快速IP设置工具网络辅助16.40 MBv1.32 免费版
详情路由器刷breed Web控制台助手网络辅助18.20 MBv5.8 通用版
详情火狐插件hackbar网络辅助235.00 KBv2.1.3 增强版
详情log日志大文件查看工具logviewer pro网络辅助1.19 MBv2.3.1 绿色版
详情百度翻译百度浏览器扩展程序网络辅助50.91 MBv1.2.4 官方最新版
详情金万维天联高级版客户端网络辅助23.29 MBv7.0.4.0 官方最新免费版
详情win10pcap网络抓包工具网络辅助1.00 MBv10.2-5002 官方版
详情chrome autofill(自动填充表单)网络辅助250.00 KBv7.8.0 免费版
详情UrlHelper中文破解版(直播源抓取工具)网络辅助1.39 MBv3.42 个人部分汉化版
详情chrome office viewer crx插件(谷歌浏览器Office控件)网络辅助3.00 KBv1.2 免费版
详情西门子环网管理工具Primary Setup Tool(PST)网络辅助82.68 MBv4.1 官方最新版
详情Bette Cloudflare IP工具网络辅助1.28 MBv2.6.1 优化版
详情Firebug(firefox插件)网络辅助2.40 MBv3.0.11 中文最新版
详情小米路由器SSH工具包网络辅助3.00 KB
详情西瓜插件新媒体管家网络辅助16.54 MBv1.1.0.2 官方版
详情mobaxterm中文版网络辅助10.30 MBv20.4 绿色破解版
详情Termius for Windows网络辅助128.00 MBv7.8.0 电脑版
详情Bus Hound(USB抓包工具) 中文版网络辅助1.43 MBv6.0.1 免费版
详情谷歌浏览器划词翻译插件网络辅助1.70 MBv6.1.3 免费版
详情win7/win10 IPX协议自动安装器网络辅助1,023.00 KB官方最新版
详情Microsoft Silverlight 5.0网络辅助6.46 MB简体中文安装版
详情MAC地址批量生成器网络辅助478.00 KBv2.0.1 免费版
详情小鹿360点睛推广软件网络辅助20.20 MBv1.2.111.6295 官方版
详情阿拉丁淘客助手网络辅助130.00 MBv1.0.100 官方版
详情福建工程学院校园网锐捷认证客户端网络辅助28.80 MBv4.99 最新官方版
详情MentoHUST锐捷认证工具网络辅助1.11 MBv4.1.0.2001 官方免费版
详情点击查看更多
Global Speed(网页视频加速插件)网络辅助404.00 KB免费版
详情huhamhire-hosts(Google Hosts更新工具)网络辅助9.27 MB2020 最新版
详情暴力猴插件(Violent monkey)网络辅助571.00 KBv2.13.0 免费版
详情Proxifier(socks5客户端)网络辅助3.47 MBv3.42 汉化优化安装版
详情win7/win10 IPX协议自动安装器网络辅助1,023.00 KB官方最新版
详情易大师网络工具箱网络辅助1.30 MBv2018.12.18 绿色版
详情Aircrackng(无线破解工具)网络辅助7.10 MBv1.5.2 中文免费版
详情ghelper上网助手网络辅助362.00 KBv2.6.2 最新版
详情谷歌百度翻译chrome插件网络辅助242.00 KBv1.2 免费版
详情NetCat网络剪刀手网络辅助1.70 MBv2.08 汉化版
详情谷歌上网助手google helper插件网络辅助362.00 KBv2.6.2 最新版
详情老密查询工具(qq历史密码查询系统)网络辅助2.15 MBv1.0 绿色版
详情换ip软件永久免费(ip地址随意换)网络辅助1.46 MBv3.4 简体中文绿色版
详情Adobe flash player Plugin(非IE内核)网络辅助153.09 MBv33.0.0.401 官方正式版
详情FVD Video Downloader网络辅助944.00 KBv6.5.1 最新版
详情chrome office viewer crx插件(谷歌浏览器Office控件)网络辅助3.00 KBv1.2 免费版
详情chrome autofill(自动填充表单)网络辅助250.00 KBv7.8.0 免费版
详情ip攻击器让别人掉线(LAN Destruction)网络辅助453.00 KBv1.0 绿色版
详情网卡地址修改器网络辅助707.00 KBv2.0.8.3 绿色免费版
详情斐讯K2最新刷机固件(附华硕潘多拉固件)网络辅助26.20 MBv22.4.5.39 官方版
详情万能注册机(序列号生成器软件)网络辅助69.00 MB免费绿色版
详情纯真ip数据库网络辅助4.64 MBv2022.04.20 中文最新版
详情tv盒子助手(乐视盒子助手)网络辅助6.67 MBv3.0.42.1 官方版
详情锐捷校园网客户端网络辅助9.86 MBv4.10 官网电脑版
详情酷繁抢币助手(酷狗繁星抢币)网络辅助7.00 MBv4.0.1.0 免费版
详情路由器刷breed Web控制台助手网络辅助18.20 MBv5.8 通用版
详情内网通积分码注册器网络辅助290.00 KB最新免费版
详情海康威视activex控件网络辅助2.09 MB官方版
详情Microsoft Silverlight 5.0网络辅助6.46 MB简体中文安装版
详情红蜘蛛多媒体网络教室7.2破解版网络辅助19.58 MBv7.2 build 1208 特别版
详情火绒弹窗拦截工具独立版网络辅助2.50 MBv5.0.44.8 绿色版
详情win10mac地址修改器网络辅助218.00 KBv2.0 绿色版
详情自动发qq消息(qq刷屏器)网络辅助403.00 KB免费版
详情小黑磁力搜索引擎网络辅助437.00 KBv2.0 绿色版
详情世界电子地图高清版大图网络辅助27.81 MB2019 绿色免费版
详情奥维互动地图2021完美版网络辅助55.00 MBv8.8.9 绿色版
详情xenu link sleuth(网站死链接检测工具)网络辅助536.00 KBv1.3.8 绿色免费汉化版
详情群晖web clipper网络辅助3.36 MBv2.0.0046 官方版
详情无线蹭网工具奶瓶beini网络辅助44.00 MB无限免费破解增强版_wifi奶瓶破解beini3.0
详情Stream Recorder(网页流媒体抓取)网络辅助111.00 KBv1.1.2 免费版
详情点击查看更多
P2P后台终结者网络辅助4.91 MBv2.4 官方简体中文版
详情华为stb管理工具密码网络辅助692.00 KBv4.03 中文版
详情世纪前线测速(Avltool网速测试)网络辅助537.00 KBv3.00 绿色版
详情局域网地址检测器网络辅助990.00 KB绿色免费版
详情Proxifier(socks5客户端)网络辅助3.47 MBv3.42 汉化优化安装版
详情纯真ip数据库网络辅助4.64 MBv2022.04.20 中文最新版
详情百度网盘极速上传控件网络辅助440.00 KBv2.0.0.3 正式版
详情逆火网站日志分析器破解版网络辅助127.00 MBv4.18 企业版
详情袜子贴吧盖楼机网络辅助2.44 MBv3.7.1.1101 绿色免费版
详情傲杰关键字排名查询系统百度专版网络辅助3.00 MBv3.0 官方版
详情迅雷软件助手网络辅助5.89 MBv1.0.4.402 官方版
详情群晖web clipper网络辅助3.36 MBv2.0.0046 官方版
详情金手指工具pec汉化版网络辅助878.00 KB最新免费版
详情腾讯QQ工具栏网络辅助1.75 MBv5.0.1.5 简体中文安装版
详情ajax debugger(Chrome插件)网络辅助50.00 KBv1.0.4 免费版
详情电视应用安装器网络辅助4.22 MBv1.3.7.28 官方版
详情steam账号切换器(steam account switcher)网络辅助38.00 KBv1.0.0 绿色免费版
详情超级自动注册申请王网络辅助15.44 MBv3.1.0 免费版
详情残月WiFi无线网络管理器网络辅助478.00 KBv1.7绿色版
详情速改通ip转换修改器网络辅助3.74 MB
详情dns锁定工具(DNS Lock)网络辅助404.00 KBv1.3 绿色免费版
详情yy影身马甲工具网络辅助9.68 MBv1.0 绿色版
详情ThinkSNS(社交系统)网络辅助20.70 MBv4.5 最新官方版
详情无线蹭网防护器网络辅助1.22 MBv4.1 绿色版
详情西祠胡同站内信(飞语)群发软件网络辅助2.06 MBv2.6 官方免费版
详情网页爬虫Web Scraper网络辅助1.50 MBv0.6.1 官方版
详情网站关键字查询工具网络辅助10.65 MBv6.5.0.0 官方最新版
详情超级兔子ie守护天使网络辅助21.64 MBv11.0.10.0 简体中文版
详情网卡地址修改器网络辅助707.00 KBv2.0.8.3 绿色免费版
详情阿里蜘蛛池(alispider)网络辅助14.23 MBv3.0 免费版
详情小米云相册助手网络辅助14.95 MBv1.2.2 官方安装版
详情360浏览器比价插件网络辅助381.00 KB官方最新版
详情飞飞ip详细地址查询网络辅助878.00 KBv1.1 绿色免费版
详情电视apk局域网安装器网络辅助3.31 MBv1.0 绿色免费版
详情金山电脑使用痕迹清理工具网络辅助4.94 MB独立绿色版
详情网吧幽灵万象2009(终极破解万象所有版本)网络辅助584.00 KB绿色免费版
详情奥维地图企业版网络辅助16.60 MBv2.3.1 免费版
详情绿茶网页自动登录器网络辅助12.30 MBv3.0 绿色免费版
详情湖南电信10000管家网络辅助13.10 MBv7.0.1.0 官方最新版
详情X-Router超级路由器网络辅助24.12 MBv7.5.3 官方免费版
详情点击查看更多