疯子页面采集(提取链接)
绿色版大小:1.99 MB更新:2019/01/22
类别:网络辅助系统:Winll
分类分类
大小:1.99 MB更新:2019/01/22
类别:网络辅助系统:Winll
疯子页面采集器是非常使用的站长工具,直接解压压缩包就能开始使用.这里小编为大家带来详细的页面采集教程,不会使用的小伙伴可以参考一下.疯子页面采集器亮点就是除了能抓取文字内容还能直接采集图片.欢迎感兴趣的用户来IT猫扑下载应用!
本程序不需要安装
电脑用不了本程序请点击&配置信息,接着点击&环境配置&选项即可.
测试程序免费使用,使用正式版程序100元,要求提供源码150元,代写采集代码250元
本程序只是测试程序,隐藏了部分功能,需要全部功能请qq联系买正式版程序
配置了还是用不了请联系qq调试,调试不收财,加好友请备注:疯子
正式版程序只能在一台电脑使用,换电脑或者电脑坏了需要重新买序列号25元
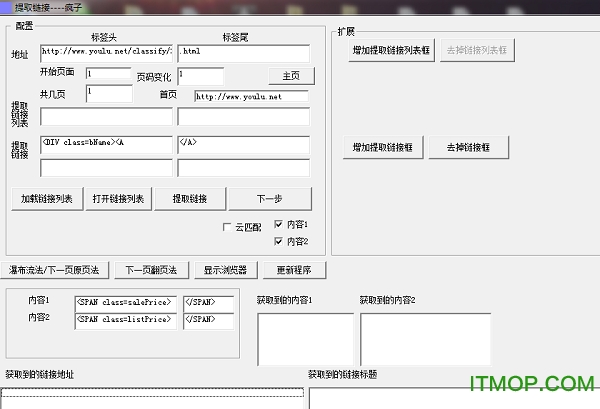
它可以帮助用户轻松的进行网站信息采集,网站信息抓取,包括图片、文字等信息采集处理发布,它也是是目前使用人数最多的互联网数据采集程序,能够采集大部分未加密页面站点.

【第一步】
填写&链接开始&,0就是第一个链接,4就是第五个链接,这里填0
填写&地址变化&,比如4就会采集第1、5、9...的链接,这里填1
&保存图片&:采集图片,如果选择打钩保存图片地址,
就必须填写首页地址,就是要采集的网站的首页地址,没有填写保存图片会出错
&图片本地化&:把图片保存到服务器
点击&浏览器&,在地址栏输入内容页地址
比如
http://www.youlu.net/2837850
等网页加载完再点击代码,
把代码复制粘贴到dreamweaver或别的网页编辑器打开方便浏览,
ctrl+a是全选,ctrl+C是复制,ctrl+v是粘贴
【第二步:填写内容】
填写内容规则,在代码中找到内容的开始标签和结束标签
标签头
<H3>图书详情</H3></DIV>
ghelper上网助手网络辅助362.00 KBv2.6.2 最新版
详情Aircrackng(无线破解工具)网络辅助7.10 MBv1.5.2 中文免费版
详情Microsoft Silverlight 5.0网络辅助6.46 MB简体中文安装版
详情Global Speed(网页视频加速插件)网络辅助404.00 KB免费版
详情科达IPCSearch工程配置工具网络辅助7.50 MBv3.0.181002 官方版
详情海康dvr监控在线观看插件(WebComponents.exe)网络辅助1.28 MBv3.0.4.6 官方版
详情chrome autofill(自动填充表单)网络辅助250.00 KBv7.8.0 免费版
详情Bus Hound(USB抓包工具) 中文版网络辅助1.43 MBv6.0.1 免费版
详情MAC地址修改器网络辅助504.00 KBv1.1 绿色版
详情win7/win10 IPX协议自动安装器网络辅助1,023.00 KB官方最新版
详情万能注册机(序列号生成器软件)网络辅助69.00 MB免费绿色版
详情百度药丸 chrome 插件网络辅助137.00 KBv2.2.2 官方版
详情网卡地址修改器网络辅助707.00 KBv2.0.8.3 绿色免费版
详情win10mac地址修改器网络辅助218.00 KBv2.0 绿色版
详情Office Editing(office在线编辑)网络辅助11.70 MBv120.2070.2080.1 免费版
详情FVD Video Downloader网络辅助944.00 KBv6.5.1 最新版
详情NetCat网络剪刀手网络辅助1.70 MBv2.08 汉化版
详情Cyotek WebCopy(网站复制工具)网络辅助4.30 MBv1.6.0.559 正式版
详情红蜘蛛多媒体网络教室7.2破解版网络辅助19.58 MBv7.2 build 1208 特别版
详情advanced ip scanner汉化版(局域网IP扫描)网络辅助8.80 MBv2.4 绿色版
详情点击查看更多
Global Speed(网页视频加速插件)网络辅助404.00 KB免费版
详情huhamhire-hosts(Google Hosts更新工具)网络辅助9.27 MB2020 最新版
详情暴力猴插件(Violent monkey)网络辅助571.00 KBv2.13.0 免费版
详情Proxifier(socks5客户端)网络辅助3.47 MBv3.42 汉化优化安装版
详情win7/win10 IPX协议自动安装器网络辅助1,023.00 KB官方最新版
详情易大师网络工具箱网络辅助1.30 MBv2018.12.18 绿色版
详情Aircrackng(无线破解工具)网络辅助7.10 MBv1.5.2 中文免费版
详情ghelper上网助手网络辅助362.00 KBv2.6.2 最新版
详情谷歌百度翻译chrome插件网络辅助242.00 KBv1.2 免费版
详情NetCat网络剪刀手网络辅助1.70 MBv2.08 汉化版
详情谷歌上网助手google helper插件网络辅助362.00 KBv2.6.2 最新版
详情老密查询工具(qq历史密码查询系统)网络辅助2.15 MBv1.0 绿色版
详情换ip软件永久免费(ip地址随意换)网络辅助1.46 MBv3.4 简体中文绿色版
详情Adobe flash player Plugin(非IE内核)网络辅助153.09 MBv33.0.0.401 官方正式版
详情FVD Video Downloader网络辅助944.00 KBv6.5.1 最新版
详情chrome autofill(自动填充表单)网络辅助250.00 KBv7.8.0 免费版
详情chrome office viewer crx插件(谷歌浏览器Office控件)网络辅助3.00 KBv1.2 免费版
详情ip攻击器让别人掉线(LAN Destruction)网络辅助453.00 KBv1.0 绿色版
详情网卡地址修改器网络辅助707.00 KBv2.0.8.3 绿色免费版
详情斐讯K2最新刷机固件(附华硕潘多拉固件)网络辅助26.20 MBv22.4.5.39 官方版
详情点击查看更多
P2P后台终结者网络辅助4.91 MBv2.4 官方简体中文版
详情华为stb管理工具密码网络辅助692.00 KBv4.03 中文版
详情世纪前线测速(Avltool网速测试)网络辅助537.00 KBv3.00 绿色版
详情局域网地址检测器网络辅助990.00 KB绿色免费版
详情Proxifier(socks5客户端)网络辅助3.47 MBv3.42 汉化优化安装版
详情纯真ip数据库网络辅助4.64 MBv2022.04.20 中文最新版
详情百度网盘极速上传控件网络辅助440.00 KBv2.0.0.3 正式版
详情逆火网站日志分析器破解版网络辅助127.00 MBv4.18 企业版
详情袜子贴吧盖楼机网络辅助2.44 MBv3.7.1.1101 绿色免费版
详情傲杰关键字排名查询系统百度专版网络辅助3.00 MBv3.0 官方版
详情迅雷软件助手网络辅助5.89 MBv1.0.4.402 官方版
详情群晖web clipper网络辅助3.36 MBv2.0.0046 官方版
详情金手指工具pec汉化版网络辅助878.00 KB最新免费版
详情腾讯QQ工具栏网络辅助1.75 MBv5.0.1.5 简体中文安装版
详情ajax debugger(Chrome插件)网络辅助50.00 KBv1.0.4 免费版
详情电视应用安装器网络辅助4.22 MBv1.3.7.28 官方版
详情steam账号切换器(steam account switcher)网络辅助38.00 KBv1.0.0 绿色免费版
详情超级自动注册申请王网络辅助15.44 MBv3.1.0 免费版
详情残月WiFi无线网络管理器网络辅助478.00 KBv1.7绿色版
详情速改通ip转换修改器网络辅助3.74 MB
详情点击查看更多