
tesseract ocr 中文版
v4.0.0 官方版大小:41.86 MB更新:2018/04/19
类别:文字处理系统:Winll
分类分类
大小:41.86 MB更新:2018/04/19
类别:文字处理系统:Winll
tesseract-ocr是一款ocr文字识别软件,能够快速将图片文字进行识别提取,从转换成电子文档,tesseract ocr windows常适用于印刷行业;另外国内多种包含ocr技术的软件,例如清华文通、汉王等也都是非常不错的。有需要的朋友欢迎来IT猫扑下载吧。
Tesseract可以在Linux,Windows(用VC++Express或CygWin)和Mac OSX上运行。它也可以在其他平台上编译,包括Android和iPhone,虽然这些都不是行之有效的平台。其他项目也可以用插件页面在各种平台上使用Tesseract。
下载完后进行安装,默认情况下安装程序会给你配置系统环境变量,以指向安装目录(之后可以通过DOS界面在任意目录运行tesseract)。
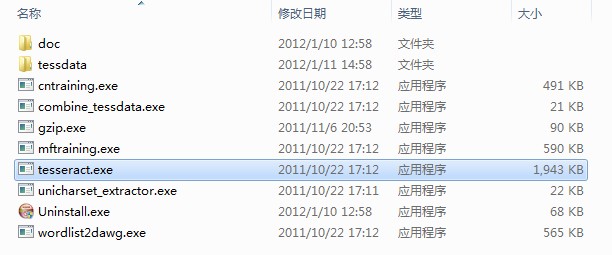
tessdata 目录存放的是语言字库文件,和在命令行界面中可能用到的参数所对应的文件. 这个安装程序默认包含了英文字库。
使用Tessract-OCR引擎识别验证码
打开DOS界面,输入tesseract:
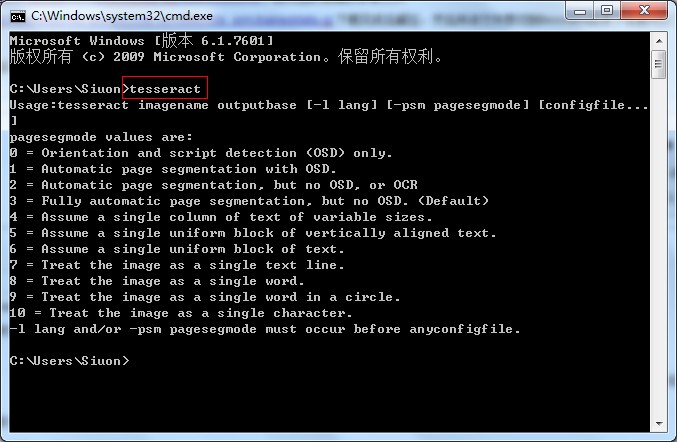
如果出现如上输出,表示安装正常。
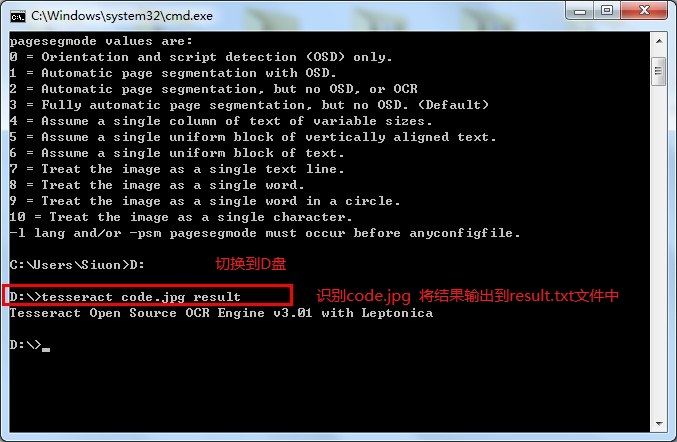
我准备了一张验证码code.jpg![]() 放在D盘根目录下
放在D盘根目录下
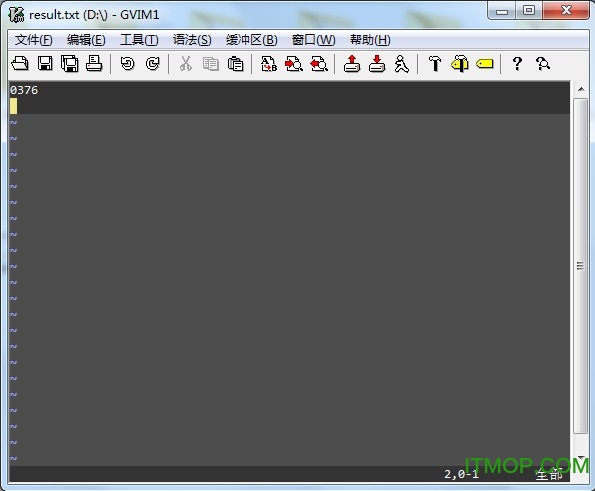
附录:
Usage:tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
pagesegmode values are:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
-l lang and/or -psm pagesegmode must occur before anyconfigfile.
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
例如:
tesseract code.jpg result -l chi_sim -psm 7 nobatch
-l chi_sim 表示用简体中文字库(需要下载中文字库文件,解压后,存放到tessdata目录下去,字库文件扩展名为 .raineddata 简体中文字库文件名为: chi_sim.traineddata)
-psm 7 表示告诉tesseract code.jpg图片是一行文本 这个参数可以减少识别错误率. 默认为 3
configfile 参数值为tessdataconfigs 和 tessdatatessconfigs 目录下的文件名
核心开发人员是Ray Smith。
在相关工作中,Thomas Breuel(tmbdev)和Ilya Mezhirov (mezhirov)开发了OCRopus项目,该项目还提供了布局分析和统计语言建模的工作。
Tesseract的大部分运作由谷歌赞助。
winhex中文版(多功能十六进制编辑器)文字处理2.25 MBv20.4 SR-5 中文专业绿色版
详情acrobat xi pro注册机文字处理85.00 KB绿色版
详情abbyy finereader 14绿色版文字处理409.00 MB含破解补丁
详情editplus 64位破解版文字处理2.60 MBv5.3.0.3080 汉化绿色特别版
详情Adobe Acrobat XI Pro绿色版文字处理359.00 MBv11.0.10.32 便携中文精简版
详情Nitro PDF Professiona9中文版文字处理82.44 MBv9.0.2.38 汉化绿色版
详情ABBYY FineReader 12中文版文字处理400.00 MBv12.0.101 免费专业版
详情WinHex单文件版文字处理1.76 MBv20.2 简体中文注册版
详情abbyy finereader 12注册机文字处理986.00 KB中文免费版
详情福昕高级pdf编辑器企业版文字处理435.61 MBv9.0.0.29935 破解版_附教程
详情黑马校对v18破解版(专业文字校对)文字处理296.00 KBv18 免费版
详情EmuraSoft EmEditor Pro 64位版文字处理10.92 MBv21.5.1 汉化版
详情abbyy finereader 12破解文件文字处理986.00 KB免费版
详情迅捷PDF编辑器免费版文字处理26.37 MBv6.3.0 最新版
详情emeditor注册密钥文字处理33.40 MB免费激活版
详情汉王OCR文字识别软件文字处理45.48 MBv6.0 中文破解版
详情迅捷OCR文字识别软件免费破解版文字处理3.63 MBv7.5.8.3 电脑版
详情Typora32位/64位中文版(Markdown编辑器)文字处理39.83 MBv0.11.13 官方安装版
详情notepad++64位文字处理4.32 MBv7.5.5 中文安装版
详情EmEditor pro专业版文字处理4.99 MBv20.2.1 32Bit 汉化绿色便携版
详情点击查看更多
abbyy finereader 12注册机文字处理986.00 KB中文免费版
详情mswrd632.wpc转换器文字处理1.46 MB免费版
详情文本恢复转换器中文版文字处理2.89 MB绿色免费版
详情acrobat xi pro注册机文字处理85.00 KB绿色版
详情捷速pdf编辑器注册机文字处理15.00 KB免费版
详情网页代码字符批量替换工具文字处理16.00 KB
详情批量图像转文字文字处理36.60 MB
详情winhex中文版(多功能十六进制编辑器)文字处理2.25 MBv20.4 SR-5 中文专业绿色版
详情Adobe Acrobat XI Pro绿色版文字处理359.00 MBv11.0.10.32 便携中文精简版
详情led屏幕文字编辑工具文字处理1.86 MB绿色免费版
详情Word Viewer 2007文字处理24.07 MB简体中文免费版
详情Powerpoint View 2003文字处理5.11 MB官方免费版
详情rar文件修复工具(yodot rar repair)文字处理9.07 MBv1.0 官方版
详情航天金税字体补丁自动安装版文字处理5.50 MBv20201209 官方最新版
详情手写模拟器转换文字处理79.00 MBv3.0 免费版
详情Win10记事本文字处理1.70 MBv1.1.0.8 官方免费版
详情口袋写作pc版文字处理77.20 MBv0.1.1 官方安装版
详情汉王OCR汉字表格识别系统文字处理30.45 MBv5.0 专业联想增强版
详情tesseract ocr 中文包文字处理17.10 MBv3.04 最新版
详情Notepad2文字处理1.05 MBv4.22.03 (r4130) 汉化版
详情点击查看更多
CoCo图像转换成word文字识别工具文字处理57.03 MB绿色特别版
详情极速pdf编辑器去水印文字处理41.48 MBv2.0.1.1 中文免费版
详情EmEditor pro专业版文字处理4.99 MBv20.2.1 32Bit 汉化绿色便携版
详情黑马校对v15完整破解版(专业文字校对)文字处理5.95 MBv15 破解版
详情emeditor32位+64位专业版文字处理35.00 MBv20.9.1 最新破解版
详情多行文本批量替换工具文字处理127.00 KB绿色免费版
详情网页代码字符批量替换工具文字处理16.00 KB
详情金鸣表格文字识别大师文字处理113.27 MBv5.60.2 官方版
详情尚书7号ocr文字识别系统完全版文字处理43.38 MB中文破解版
详情楼月文本自动输入器文字处理33.00 KBv3.0 绿色免费版
详情winhex中文版(多功能十六进制编辑器)文字处理2.25 MBv20.4 SR-5 中文专业绿色版
详情gidot typesetter排版助手文字处理2.10 MBv3.1.1 绿色最新版
详情精科文字转换通文字处理957.00 KBv1.1 绿色版
详情汉王OCR汉字表格识别系统文字处理30.45 MBv5.0 专业联想增强版
详情KeyNote记事软件文字处理719.00 KBv1.6.9.345 绿色版
详情夕风OCR图片转文本识别工具文字处理611.00 KBv2.0 绿色版
详情EmEditor编辑器(EmEditor Pro)文字处理30.00 MBv20.4.4 精简版
详情捷速pdf编辑器注册机文字处理15.00 KB免费版
详情FontCreator Professional(字体制作编辑软件)文字处理47.00 MBv12.0.0.2539 中文免费版
详情PDF智能助手文字处理71.50 MBv2.0.8 官方版
详情点击查看更多





























































