hive jdbc jar包
v2.4.18 官方版大小:132.00 KB更新:2017/12/27
类别:编程辅助系统:Winll
分类分类
大小:132.00 KB更新:2017/12/27
类别:编程辅助系统:Winll
hive jdbc jar包是一款与编程、数据库相关的工具型安装包,主要用于转换与快速管理代码的储存与编写,还是挺实用的,且配套的社区服务也相对完善,更新频繁、开源免费,推荐给大家!
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。
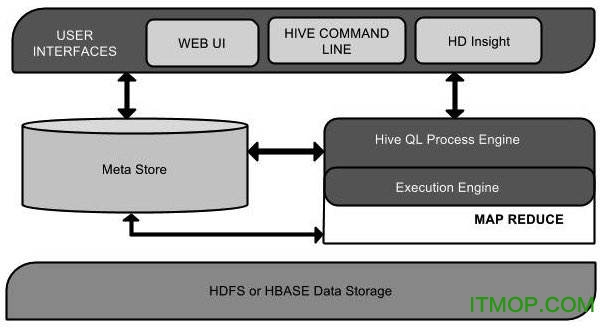
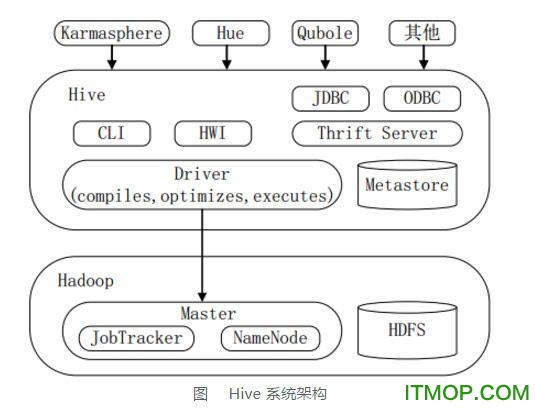
Hive 是一种底层封装了Hadoop 的数据仓库处理工具,使用类SQL 的HiveQL 语言实现数据查询,所有Hive 的数据都存储在Hadoop 兼容的文件系统(例如,Amazon S3、HDFS)中。Hive 在加载数据过程中不会对数据进行任何的修改,只是将数据移动到HDFS 中Hive 设定的目录下,因此,Hive 不支持对数据的改写和添加,所有的数据都是在加载的时候确定的。Hive 的设计特点如下。
● 将元数据保存在关系数据库中,大大减少了在查询过程中执行语义检查的时间。
● 可以直接使用存储在Hadoop 文件系统中的数据。
● 内置大量用户函数UDF 来操作时间、字符串和其他的数据挖掘工具,支持用户扩展UDF 函数来完成内置函数无法实现的操作。
● 类SQL 的查询方式,将SQL 查询转换为MapReduce 的job 在Hadoop集群上执行。
● 支持索引,加快数据查询。
● 不同的存储类型,例如,纯文本文件、HBase 中的文件。
Hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。
因此,Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
fastreport中文版(报表控件)编程辅助2.30 MBv5.6 官方最新版_含授权码/使用教程
详情VOFA+软件32位/64位编程辅助48.90 MBv1.3.10 官方版
详情大漠插件中文汉化模块源码编程辅助6.66 MB免费版
详情crystal reports 2013(水晶报表for vs2013)编程辅助232.00 MB最新免费版
详情易语言vc98linker编程辅助10.80 MB破解版
详情jstl-1.2.jar包编程辅助378.00 KB免费版
详情华为主题开发工具(hwtTool)编程辅助114.00 MBv9.1.3.302 官方版
详情Visual Assist X(vc编程辅助工具)编程辅助40.90 MBv10.9.2399 中文破解版
详情.NET代码保护工具.NET Reactor编程辅助7.27 MBv5.9.8.0 中文汉化版
详情Restorator汉化版编程辅助3.66 MBv3.7.0.1747 中文特别版
详情cxf webservice源文件+jar包编程辅助22.80 MBv3.2.0 官方版
详情Qt Designer汉化版编程辅助49.76 MB中文版
详情Mibboy社工百宝箱编程辅助96.60 MB免费版
详情WinCHM Pro(chm文件制作)编程辅助6.17 MBv5.48 汉化版
详情SDK Platform Tools for windows编程辅助6.04 MBv33.0.1 官方最新版
详情Visual Studio 2022离线工具编程辅助24.00 KBv1.0.0 免费版
详情微软.NET Framework编程辅助73.40 MBv4.7.2.0 官方完整版
详情poi-ooxml-schemas-3.9-20121203.jar编程辅助900.00 KB免费版
详情sscom42串口调试工具编程辅助340.00 KB免安装版
详情android support v7 appcompat.jar编程辅助455.00 KB官方免费版
详情点击查看更多
RxLib for D5-XE10.2 2.75 Update 1.0.17编程辅助3.90 MB
详情RedisClient(Redis客户端GUI工具)编程辅助28.59 MBv1.5.0 绿色中文版
详情odac for D7-XE6编程辅助11.70 MBv9.3.08 官方版
详情RCX-Studio(雅马哈编程软件)编程辅助9.80 MBv1.1.0 官方版
详情x64dbg调试工具编程辅助32.20 MBv2022.08.08 绿色汉化版
详情微软.NET Framework编程辅助73.40 MBv4.7.2.0 官方完整版
详情水晶报表for vs2015(CRforVS_13_0_17)编程辅助253.00 MB官方版
详情php+mysql代码生成工具编程辅助30.10 MBv1.0 绿色免费版
详情数控宏程序自动生成器编程辅助468.00 KBv3.0 免费版
详情org.apache.poi jar包编程辅助28.65 MBv3.17 官方最新版
详情mysql-connector-java-5.1.17-bin.jar(MySQL JDBC驱动包)编程辅助744.00 KB免费版
详情git for windows 64位编程辅助48.00 MBv2.32.0.2 官方最新版
详情VOFA+软件32位/64位编程辅助48.90 MBv1.3.10 官方版
详情sap crystal reports runtime engine for .net编程辅助78.00 MBv64bit 13.0.9 官方免费版
详情jQuery EasyUI编程辅助1.09 MB1.7.0 官方API中文版
详情log4j-1.2.17.jar.zip编程辅助434.00 KB官方免费版
详情fastreport中文版(报表控件)编程辅助2.30 MBv5.6 官方最新版_含授权码/使用教程
详情jstl-1.2.jar包编程辅助378.00 KB免费版
详情javax.servlet-api-4.0.1.jar编程辅助277.00 KB免费版
详情Spire.Doc for Java编程辅助81.80 MBv2.7.3 免费版
详情点击查看更多
雨田静态分析系统(c语言静态分析工具)编程辅助3.15 MBv1.5.0 免费版
详情jQuery手风琴图片相册特效插件编程辅助427.00 KB正式版
详情RegexBuddy(正则表达式处理器)编程辅助18.00 MBv4.8.2 中文免安装版
详情activation.jar.zip编程辅助76.00 KB完整免费版
详情mysql-connector-java-5.1.17-bin.jar(MySQL JDBC驱动包)编程辅助744.00 KB免费版
详情Diffinity代码对比工具编程辅助373.00 KBv0.8.7 最新版
详情sublime emmet插件编程辅助224.00 KB官方版
详情OSDLL串口调试助手编程辅助177.00 KBv20.11.19.0 绿色版
详情android材质设计图标生成器(material design icon generator plugin)编程辅助31.90 MB最新版
详情mysql connector java 5.1.16.jar(mysql数据库JDBC驱动)编程辅助743.00 KB免费版
详情commons-codec-1.5.jar编程辅助72.00 KB免费版
详情LightProxy(阿里巴巴抓包工具)编程辅助93.00 MBv1.1.40 官方版
详情sublime text 3插件包编程辅助35.90 MBv1.0 绿色免费版
详情jQuery图片图集幻灯片特效插件编程辅助1.14 MB正式版
详情Android Studio 3.4中文补丁编程辅助83.25 MB免费版
详情Android Holo Colors Generator(Android布局组件)编程辅助710.00 KB最新版
详情log4j-1.2.17.jar.zip编程辅助434.00 KB官方免费版
详情git源代码管理工具编程辅助44.00 MBv2.29.2.2 官方免费版
详情smali2javaui(smali文件转java)编程辅助6.51 MBv1.0.0.558 绿色版
详情jQuery弹出层插件fDialog编程辅助44.00 KBv1.0 正式版
详情点击查看更多