通义千问的优缺点有哪些?通义千问在实际应用中的局限性总结
2024-07-18 17:30作者:绿软小编
随着人工智能技术的飞速发展,大规模语言模型(Large Language Models, LLMs)已成为连接人类与智能世界的桥梁。通义千问,作为阿里巴巴达摩院推出的大规模语言模型,以其庞大的参数量和广泛的知识覆盖而著称。接下来,小编将从三个方面来进行深入介绍:其显著优点、分类问答表现、缺陷。旨在客观分析通义千问的优点、缺陷,并总结其在实际应用中的局限性。

通义千问的优点
通义千问拥有超过10万亿的参数量,这一规模远超许多同类模型,为其提供了强大的数据处理能力和广泛的知识覆盖。通过大规模预训练,通义千问能够理解和回答跨领域的问题,从基础科学知识到复杂行业术语,展现出高度的普适性和灵活性。作为一个大规模语言模型,通义千问不仅能够准确回答问题,还能进行文本创作、表达观点甚至撰写代码。其生成的语言流畅自然,逻辑清晰,能够满足多种应用场景的需求,如写作辅助、创意激发等。
通义千问的知识库随着时间的推移而不断更新和增加,确保了其回答的时效性和准确性。此外,阿里巴巴达摩院不断投入资源对模型进行优化,提升其性能和效率,使通义千问能够持续保持领先地位。高效的计算平台与硬件支持为通义千问提供训练支持,基于阿里巴巴达摩院自主研发的大规模分布式计算平台和含光800高性能计算芯片。这些先进的硬件和软件设施为模型的训练和运行提供了强大的支撑,确保了通义千问在处理复杂任务时的稳定性和高效性。
通义千问分类问答表现
1.自我介绍类


优点:通义千问在自我介绍时展现出了高度的专业性和自信。它不仅清晰地表明了自己的身份——来自达摩院的大规模语言模型,还详细阐述了其多功能性,包括回答问题、创作文字、表达观点及撰写代码等。这种全面的介绍有助于用户快速了解模型的基本能力和适用范围。
不足:尽管自我介绍详尽,但通义千问在回答关于其名字来源的问题时,虽然解释得较为合理,但缺乏具体的实例或案例来进一步支撑其名字背后的意义,使得解释略显抽象。
2.时事新闻类


优点:通义千问在回答“嫦娥五号”返回地球的时间时,表现出了较高的准确性,这表明它在处理基础科学知识和历史事件方面具备较好的能力。
缺陷与问题:在回答世界杯冠军和冬奥会金牌数时,通义千问给出了错误的答案。这暴露了模型在实时新闻和动态数据更新方面的不足,尤其是在处理时效性强的信息时容易出错。当被问及法国总统访华的具体日期时,通义千问表示无法回答,并透露其训练数据截止到2021年。这进一步证实了模型在知识更新方面的局限性,无法及时反映最新的时事变化。
问答错误分析:通义千问错误地将2022年世界杯冠军归为意大利,而实际冠军是阿根廷。这可能是由于训练数据中的错误或更新不及时导致的。此外,通义千问错误地指出最近一次冬奥会是2018年平昌冬奥会,并给出了错误的奖牌数。实际上,最近一次冬奥会是北京冬奥会,且平昌冬奥会的奖牌数也有误。这再次证明了模型在处理具体数字和事件时的脆弱性。
3.逻辑挑战类


优点:通义千问在处理逻辑挑战类问题时展现出了较高的智能水平。例如,在回答“鱼香肉丝是用什么鱼做的?”时,它能够准确指出这道菜并不包含鱼肉,并解释了鱼香味的来源。这种回答不仅准确,而且富有逻辑性。
不足:在回答“老鼠生病了吃老鼠药能治好吗?”时,通义千问的回答虽然强调了老鼠药的危险性,但建议“通过医疗手段和宠物保护组织来保护它们的生命”并不完全贴切,因为老鼠通常不被视为宠物。此外,在回答“跳多高才能跳过广告?”时,通义千问的回答虽然涉及了多种跳过广告的方法,但并未直接针对问题本身进行逻辑分析,而是转向了技术层面的解决方案。
4.历史比较类
优点:通义千问在处理历史比较类问题时,展现出了对历史人物及其背景知识的深刻理解。它能够准确地指出关公和秦琼分别属于不同的历史时期,并简要概述了他们的主要特点和历史地位。这种回答方式既体现了模型对历史知识的掌握,又避免了直接进行无根据的比较,显示出较高的逻辑性和专业性。
不足:尽管通义千问的回答在逻辑上是合理的,但它未能进一步探讨两者在不同历史背景下的具体贡献和影响,因此未能完全满足读者对于深入比较和了解的期望。此外,模型在回答中未能引入具体的实例或故事来丰富内容,使得回答略显单调和抽象。
5.实际应用类
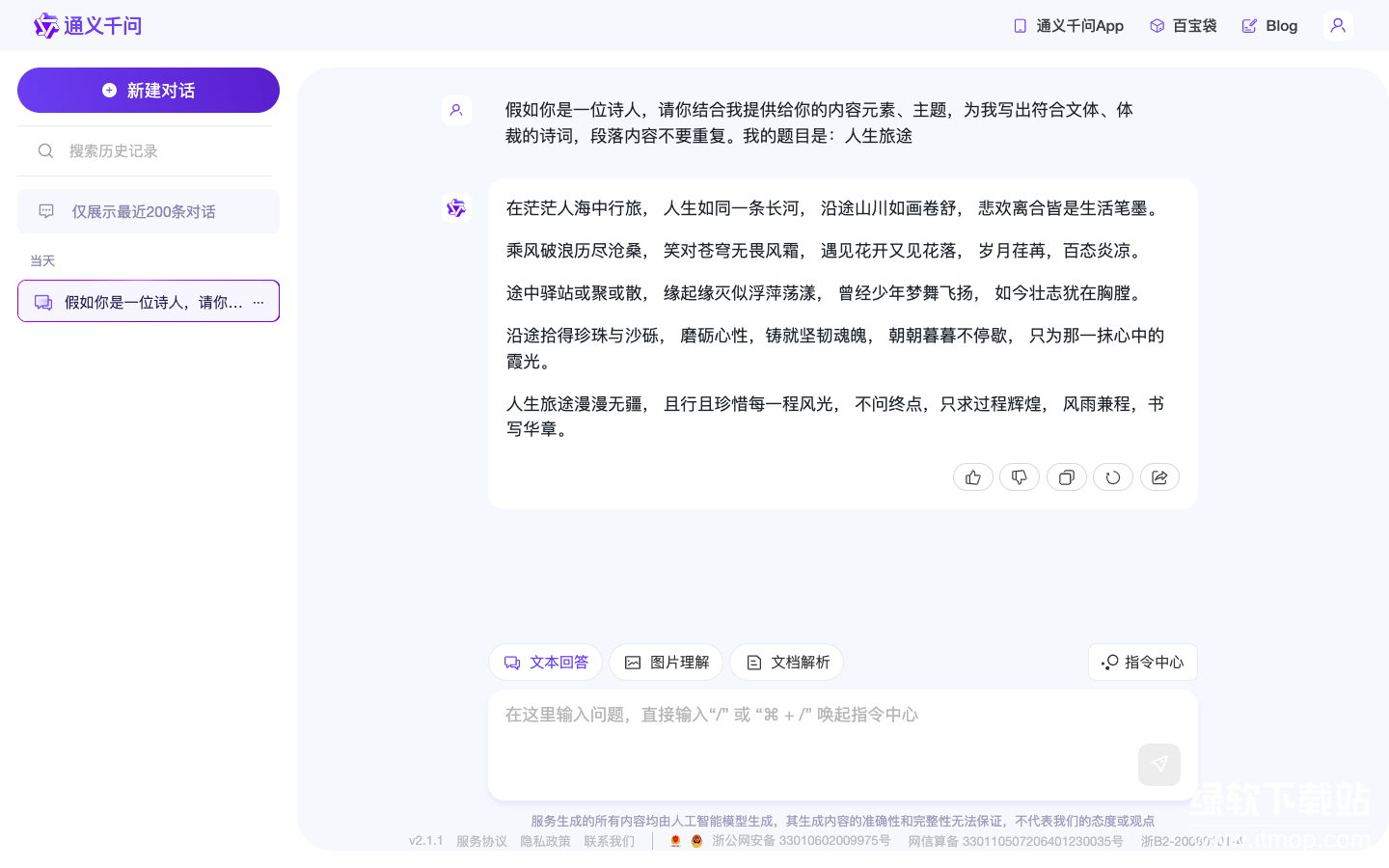

优点:在创作电影脚本时,通义千问展现出了良好的创意生成能力。它能够构建出一个完整的故事框架,包括场景设定、角色塑造和情节发展等要素,且故事具有一定的想象力和吸引力。在撰写新闻稿时,通义千问能够准确把握新闻稿的基本结构和要素,包括标题、导语、正文和结尾等部分。同时,它还能够根据主题要求,灵活地运用相关术语和表达方式,展现出对新闻写作领域的适应性。在创作公众号标题时,通义千问能够迅速捕捉到人工智能技术发展迅猛这一主题的核心要点,并创作出三个既符合主题又具有吸引力的标题。这些标题既简洁明了又富有创意,能够有效地吸引读者的注意力。
不足:在电影脚本的创作中,通义千问的回答虽然构建了一个完整的故事框架,但在细节处理上仍有待提升。例如,对于角色的性格刻画、情节的转折和冲突的设置等方面可以更加深入和具体。在新闻稿和标题的创作中,通义千问的回答虽然客观准确,但在情感表达方面略显不足。新闻稿和标题往往需要具备一定的情感色彩以吸引读者,而通义千问的回答在这方面还有待加强。
通义千问的缺陷
尽管通义千问拥有庞大的知识库,但在处理具体事实性问题时仍可能出现错误。例如,在回答“最近一次世界杯冠军”和“最近一次冬奥会中国金牌数”时,通义千问给出了错误的答案。这反映出模型在实时更新和校验知识方面的不足,尤其是在面对快速变化的时事新闻时。
对于涉及主观判断和价值观的问题,通义千问的回答往往缺乏深度和个性化。由于模型基于大量文本数据进行训练,其回答往往倾向于客观事实和数据,难以体现人类的情感、偏好和道德观念。并且,虽然通义千问能够处理跨领域的问题,但在理解复杂上下文和语境方面仍有待提高。在对话过程中,如果问题之间存在紧密的逻辑联系或需要特定的背景知识,通义千问可能无法准确理解并给出恰当的回答。
通义千问的性能在很大程度上依赖于训练数据的质量和数量。如果训练数据存在偏差或不足,模型的回答也可能出现偏差或错误。此外,模型在处理罕见或新颖问题时可能表现出较弱的泛化能力。